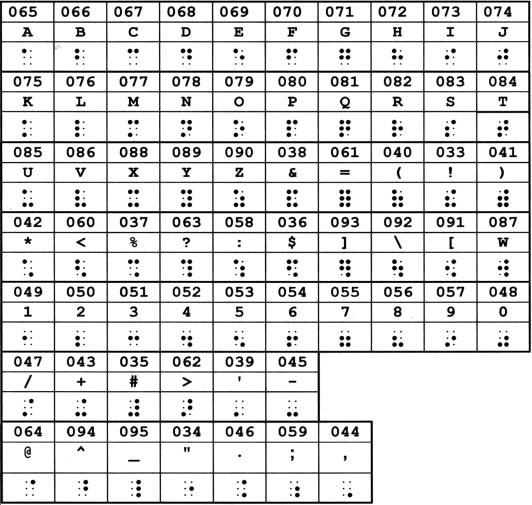
 Upper row: ASCII code (decimal)
Upper row: ASCII code (decimal)Middle row: Basic Latin character corresponding to code
Lower row: Braille cell corresponding to code
Upper row: ASCII code (decimal)
Middle row: Basic Latin character corresponding to code
Lower row: Braille cell corresponding to code
ASCII Braille is a set of numerical character codes for representing six-dot braille cells electronically; ASCII Braille is an example of a publishing code. There are numerous different ASCII braille codes—with various assignments of character codes to braille cells—although the one produced by the Duxbury Braille Translator (DBT), which is sometimes called North American or MIT ASCII Braille, is probably most widely used.
Two of the file formats that use North American ASCII braille are Braille Formatted (BRF) files and Duxbury Translator Braille (DTB) files.
ASCII Braille wasn't originally meant for humans to read. However, since it re-uses the same numerical character codes as the standard ASCII codes for the Basic Latin keyboard characters, it is effectively a transliteration of braille cells by print characters. Fifteen or so assignments have an arbitrary relationship to any common meaning of the cell but many are consistent with either the Nemeth or Grade 2 braille codes. Some assignments, such as using the ASCII code for the print question mark for dots-1456, are based on a physical similarity between the printed character and the braille cell.
Sighted people sometimes read ASCII braille as plain text by displaying it with a standard print font. ASCII braille can also be displayed as blackprint dots by using a consistent braille font. Duxbury's SimBraille© and Braille fonts are consistent with North American ASCII Braille.
ASCII Braille is displayed tactilely by using the appropriate Display Table to interface with an embosser or refreshable braille display.
ASCII Braille is convenient in that it supports direct entry of braille from a standard keyboard. However, the strategy of re-using the same character codes for multiple purposes—which was necessary with older computer hardware—is being phased out on the Web since it complicates the use of multiple languages. (You can read about the Web Internationalization Activity on the World Wide Web Consortium site.) The Unicode project supports Internationalization by defining unique character codes for almost 100,000 characters and symbols.
This page was first posted November 30, 2002.
Send feedback and questions to info@dotlessbraille.org